- Create a Flexible Evaluation Datasets with test cases that have multiple inputs and expected outputs of various types
- Generate Flexible Outputs from your application that can contain multiple outputs of complex types
- Attach Traces to Outputs to record the intermediate step your application took to arrive at the final output
- Attach Metrics to Outputs to record numerical values associated with the output, such as custom automatic evaluations
- Customizing the annotation UI to allow human annotators to see the data that is relevant for them to annotate.
📘 Before you dive into the details: You may want to look at the Flexible Evaluation Recipe or the Simple Flexible Evaluation Guide to get a feel for how flexible evaluation can be used. To understand when to use flexible evaluation, see Why Use Flexible Evaluation.
Flexible Evaluation Datasets
To get started with flexible evaluations, you need a new evaluation dataset withschema_type="FLEXIBLE":
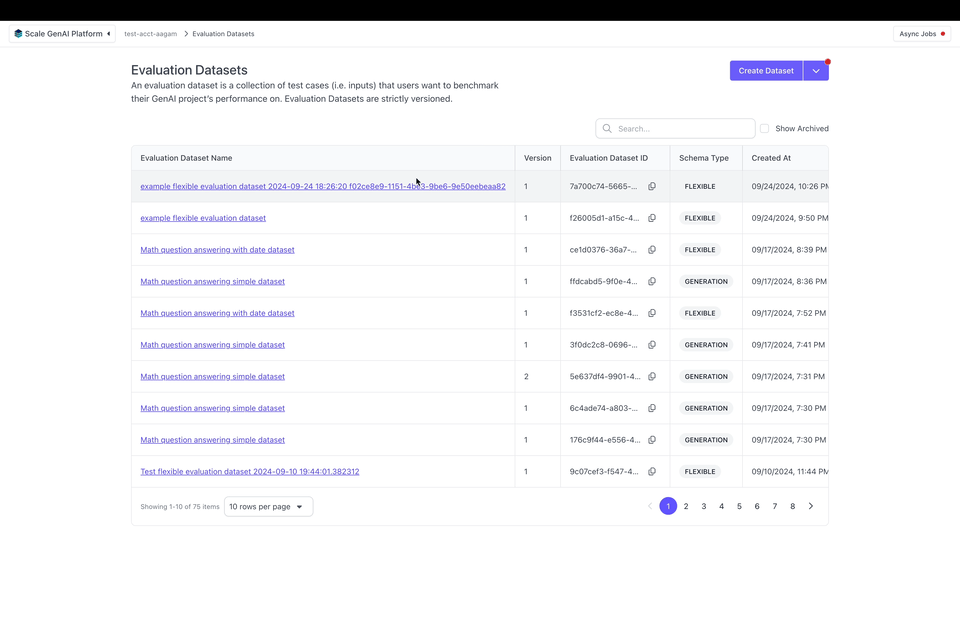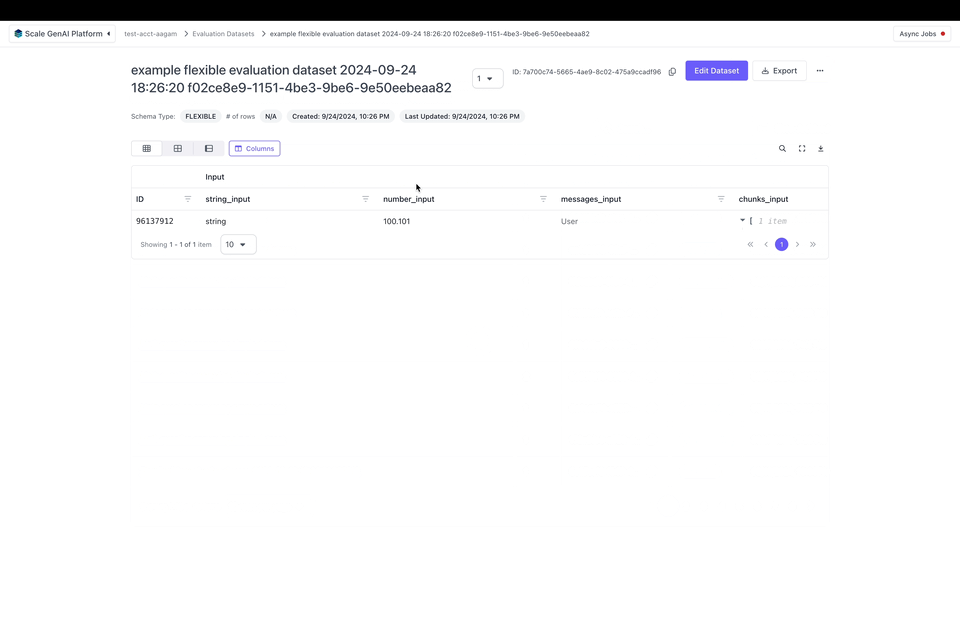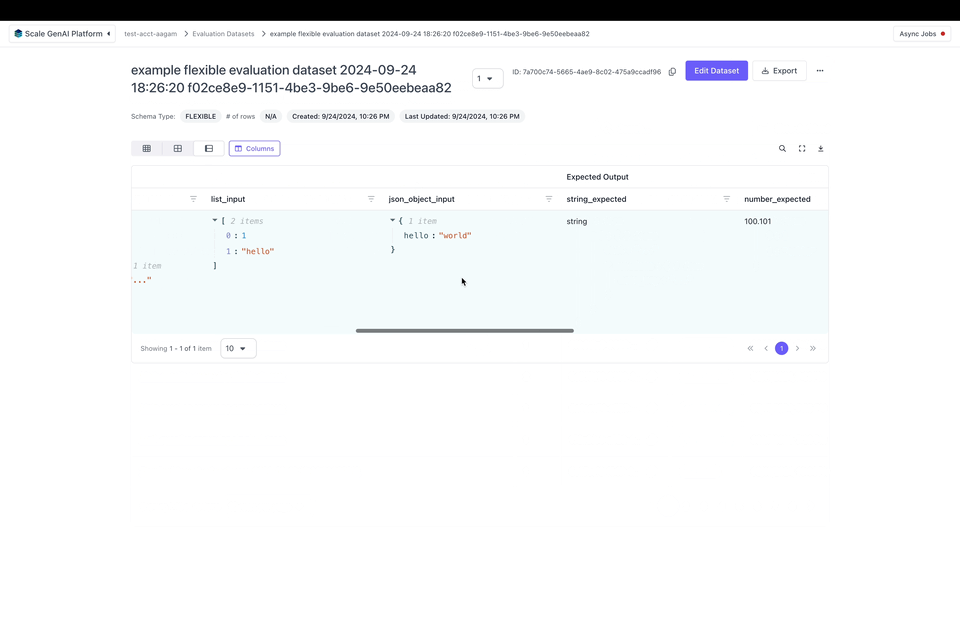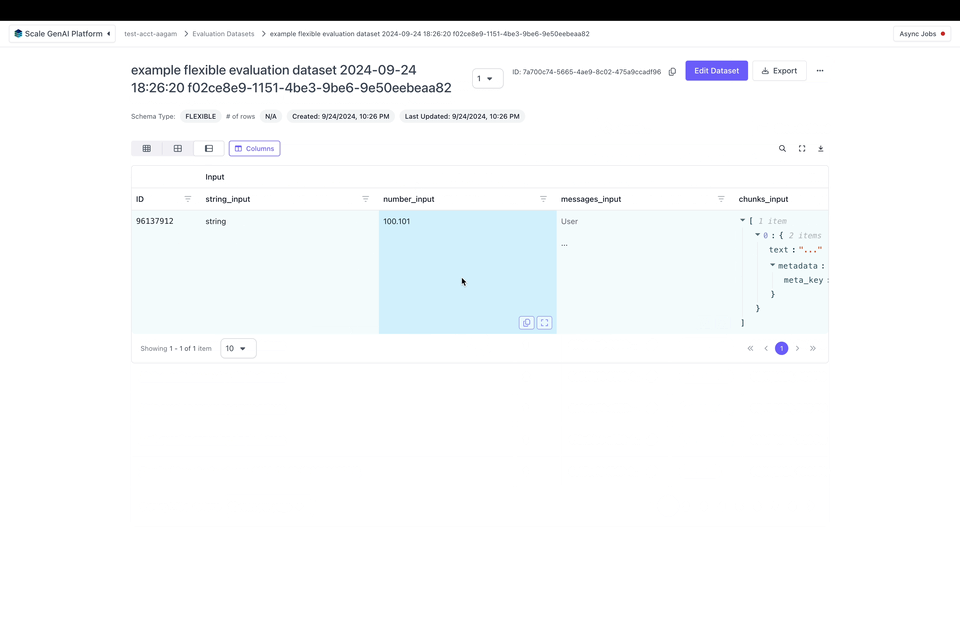
schema_type="GENERATION") datasets can only have strings as input and expected_output. Flexible evaluation datasets allow for input and expected_output to be a dictionary where each key is a string and each value is one of the following:
- String
- Number (i.e., integer or float)
- Messages (list of objects with “role” and “content” fields)
"role":"user","assistant", or"system""content": string- Example:
- Chunks (list of objects with “text” and optionally a “metadata” field)
"text": string"metadata": dictionary of strings to any JSON value- Example:
- List of any JSON value
- Example:
- JSON object
- Example:
{"key": "value"} - Example:
{"key": [{"nested": {"hello": "world"}}]}
- Example:
Flexible Outputs
After you create a flexible evaluation dataset, you can create a test case output for each input which represent the outputs from running an application on a test case. Before you do this, you’ll need to create an external application so you can tie your test case outputs to the application. Test case outputs generated from flexible evaluation datasets can also accept a dictionary where each key is a string and each value is one of (just like in flexible test cases):- String
- Number
- Messages
- Chunks
- List of any JSON value
- JSON object
Attaching Traces to Outputs
While having multiple inputs and outputs helps, many complex or agentic AI applications have multiple intermediate steps (e.g. reasoning, retrieval, tool use) that are crucial to evaluate so we can understand what’s happening inside our application. Attaching traces to test case outputs allows us to record all of these intermediate steps. A trace keeps a record of the inputs and outputs of every step as your application executes. It’s operation input and operation output must be a dictionary of string keys to values of type string, number, messages, etc., just like the input to flexible test cases.Attaching Custom Metrics to Outputs
📘 Note that custom metrics can be used for any external app — you don’t need a flexible evaluation dataset or tracesYou can also attach custom metrics to outputs. Metrics are numerical values that can be used to record, e.g., how many tokens it took to generate an output or calculated evaluation metrics like F1 or BLEU scores. Metrics can be passed as a dictionary mapping a string key to a numeric value:
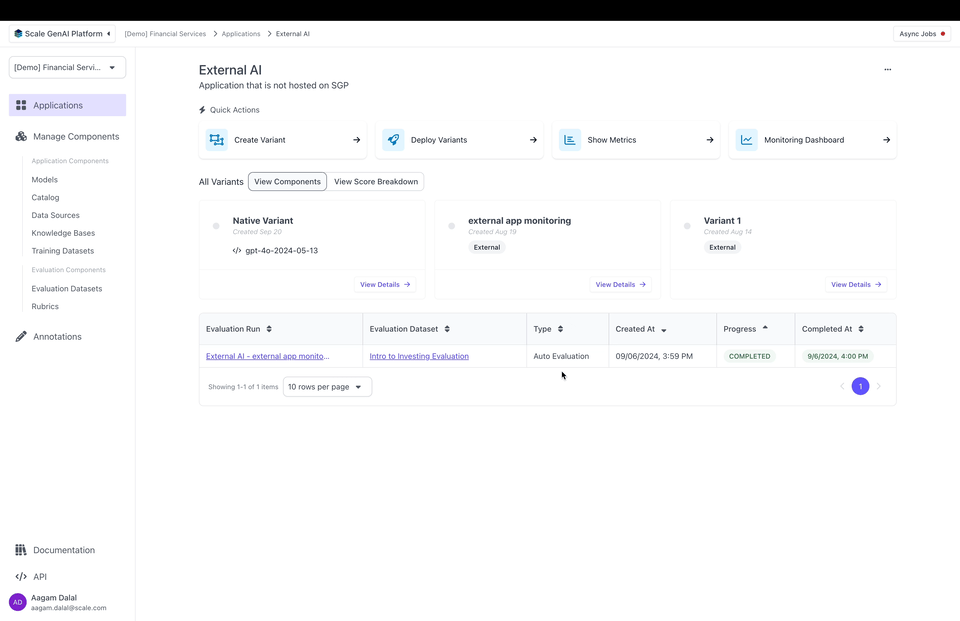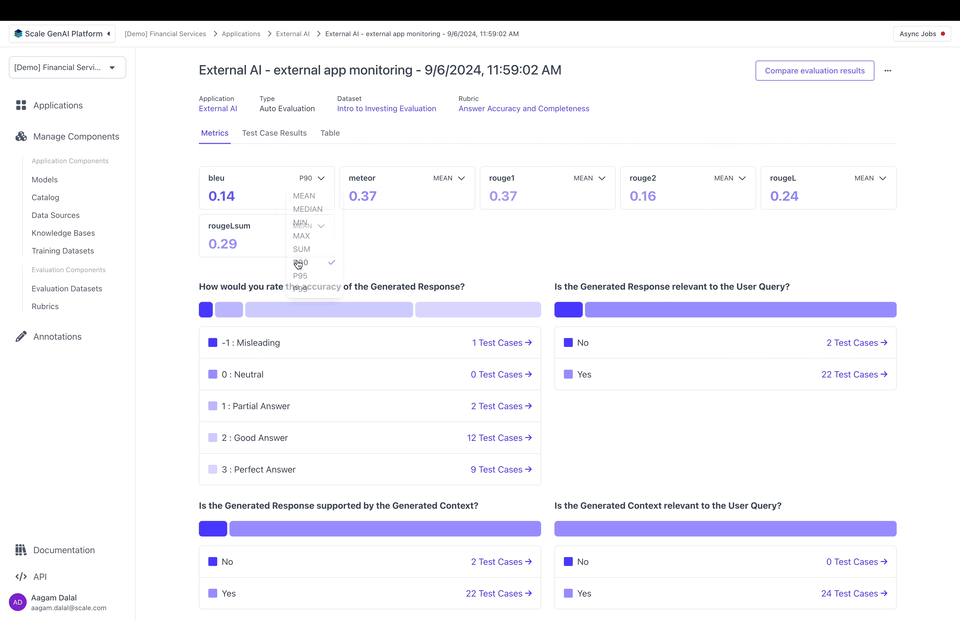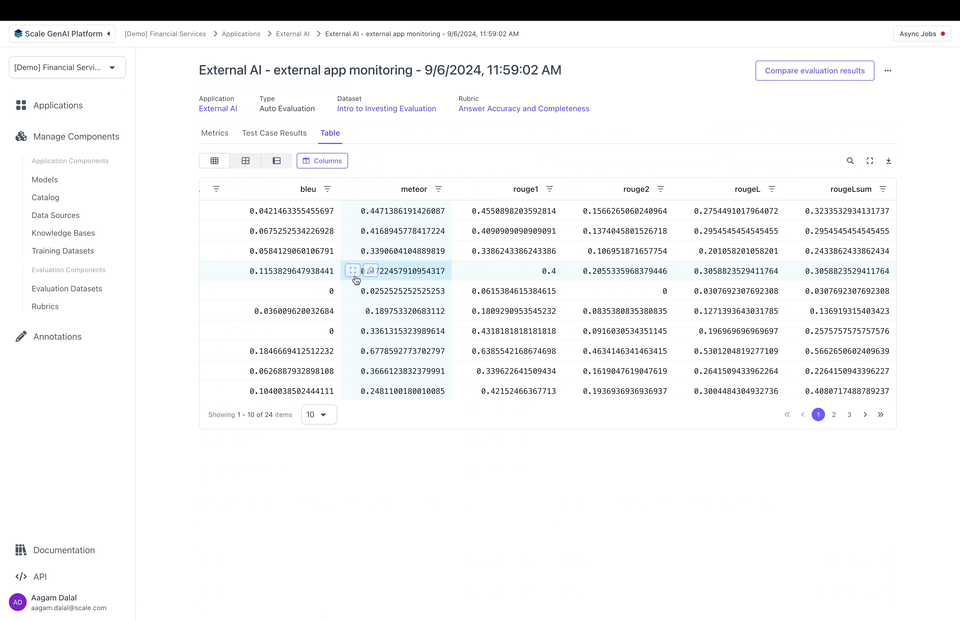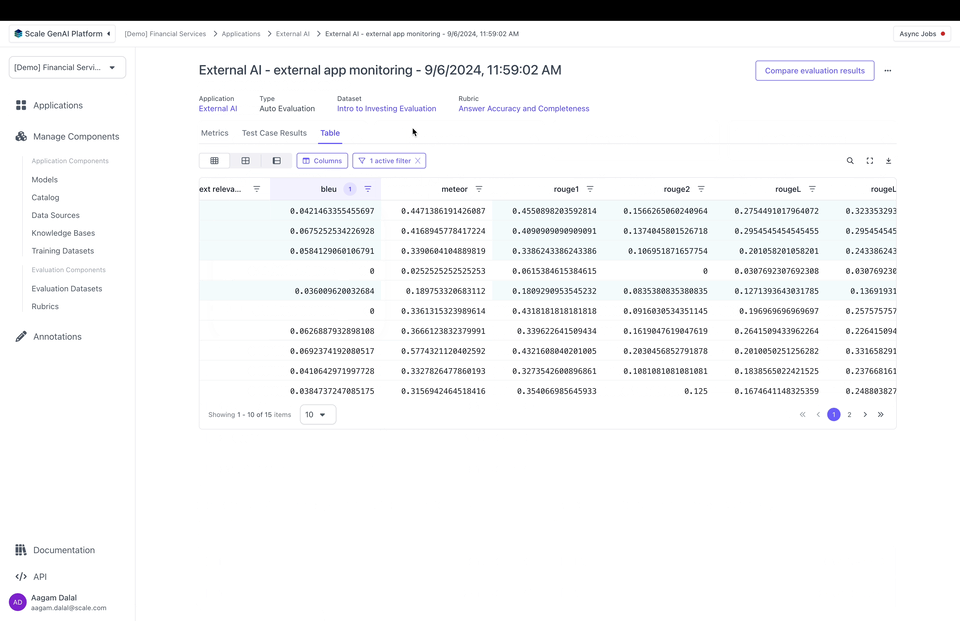
Create a custom Annotations UI
By default, the annotation UI which annotators see in SGP shows the test case input, expected output, and output. However, for complex evaluations may want to:- display data from the trace
- select which parts of test case inputs and test case outputs to display
- modify the layout the annotation UI