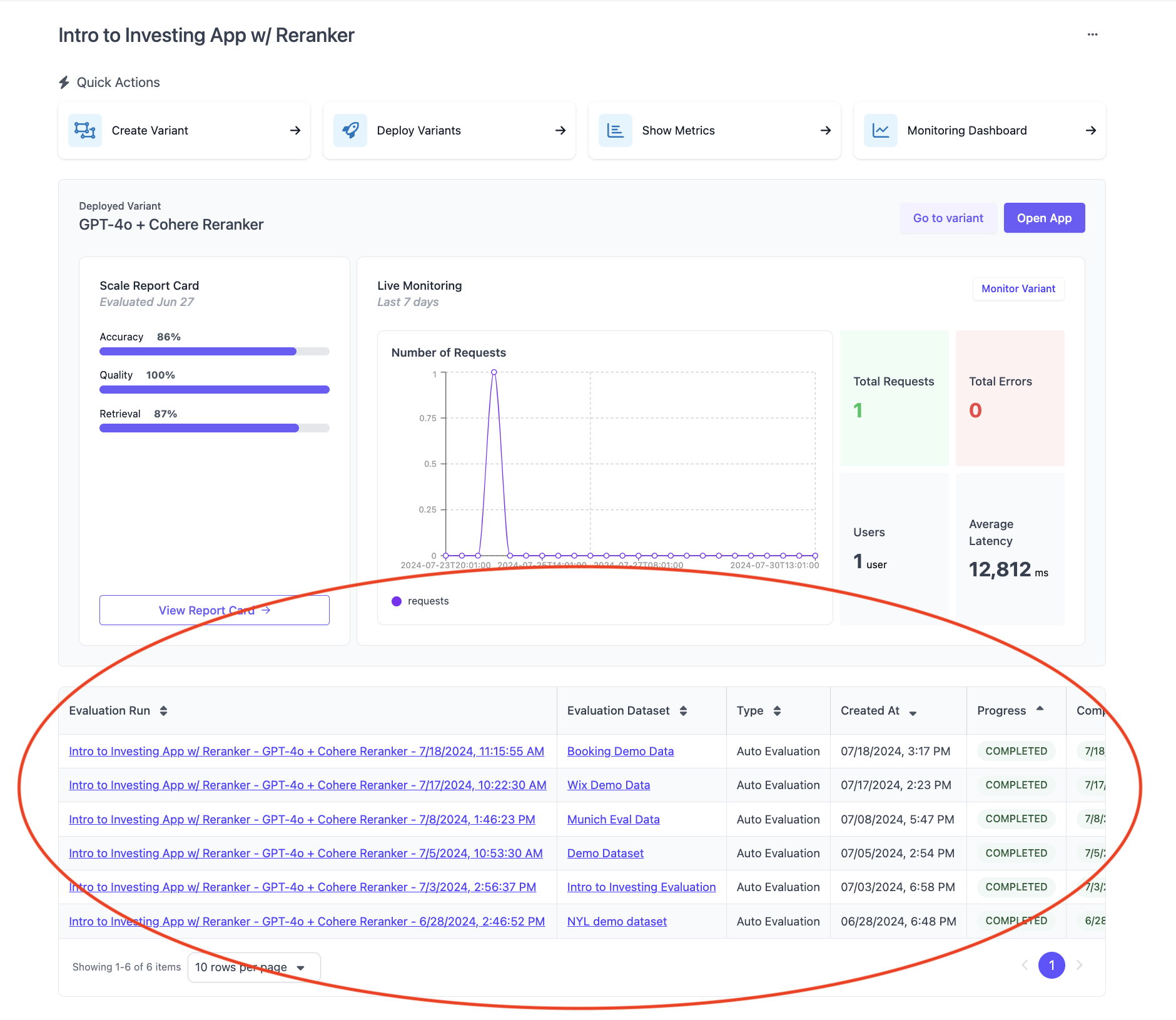
Evaluations Overview
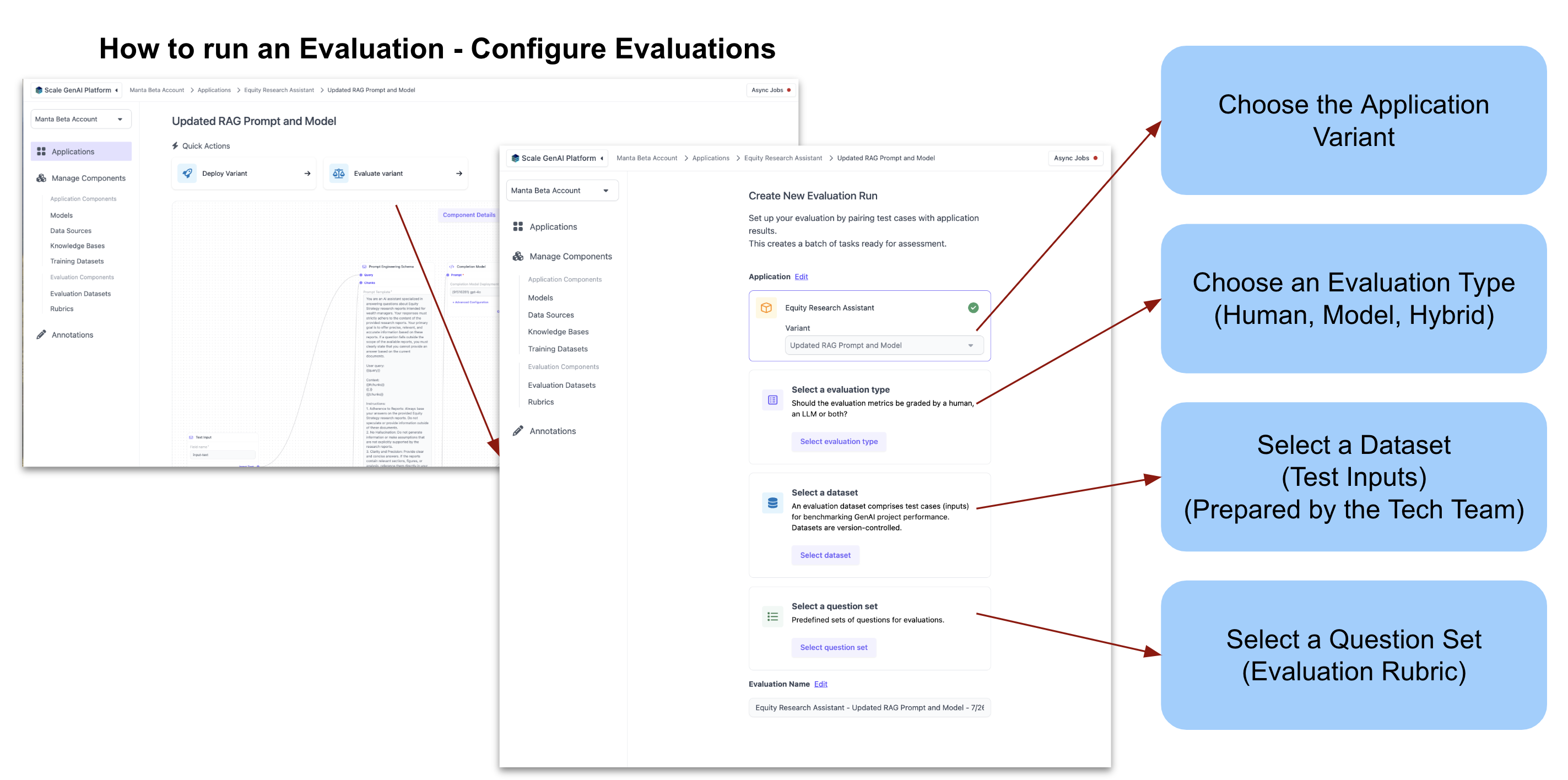
Evaluations can be run on any application variant to determine the performance of that variant. If several variants of an application are run against the same dataset and rubric, their performance can be directly compared through the platform tools. Each evaluation consists of an evaluation dataset, question set, and evaluation method.- Evaluation Dataset: A set of test cases (consisting of inputs and expected outputs along with some extra data) that is used to run an application against. See here for the format of these datasets.
- Question Set: A set of questions used to evaluate the results of the evaluation dataset. Each test case in the evaluation dataset is evaluated by the questions in each question set. Questions in the question set can pertain to the performance of the LLM such as correctness, context relevance, hallucination, trust and safety, etc.
- Evaluation Method: After the application is run against the evaluation dataset, the output needs to be evaluated against the question set to determine the performance of the application. This evaluation can be done by either an LLM, a human, or both (hybrid).
Starting an Evaluation Run
Evaluation runs can be started from the Application Variant Page.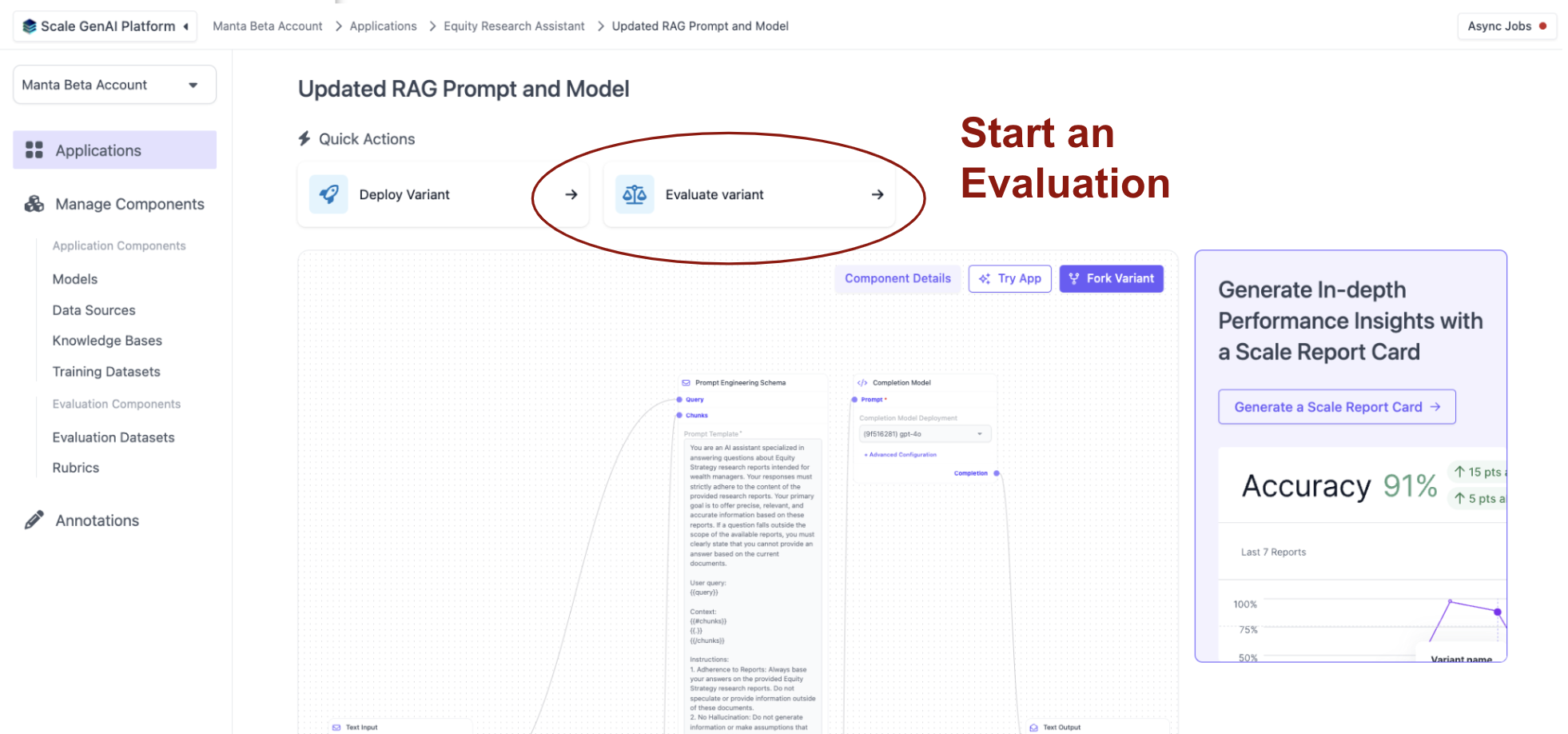
Evaluation Run Progress
After kicking off the evaluation, you can view the progress on the Applications Page.