The Simplest Possible Workflow
What It Does
This simple workflow is ideal for cases where you want to directly query the LLM with a user’s input without any additional formatting or processing. It takes the user’s question, sends it to the LLM, and returns the generated response.How It Works
-
Single Node Process: This workflow consists of one node named
query_llmthat is of typegeneration. It is designed to take a user’s question (provided asuser_question) and generate an answer directly using an LLM. -
Configuration Details:
- llm_model: Uses the
"gpt-4o-mini"model. - max_tokens: Limits the response to 64 tokens.
- temperature: Set to
0.2to control randomness in the response (lower values yield more deterministic outputs).
- llm_model: Uses the
-
Input Mapping: The node expects an input under the key
input_prompt. In this workflow,input_promptis mapped directly touser_question, meaning that whatever question is supplied by the user will be forwarded as the prompt to the LLM.
Connecting Nodes
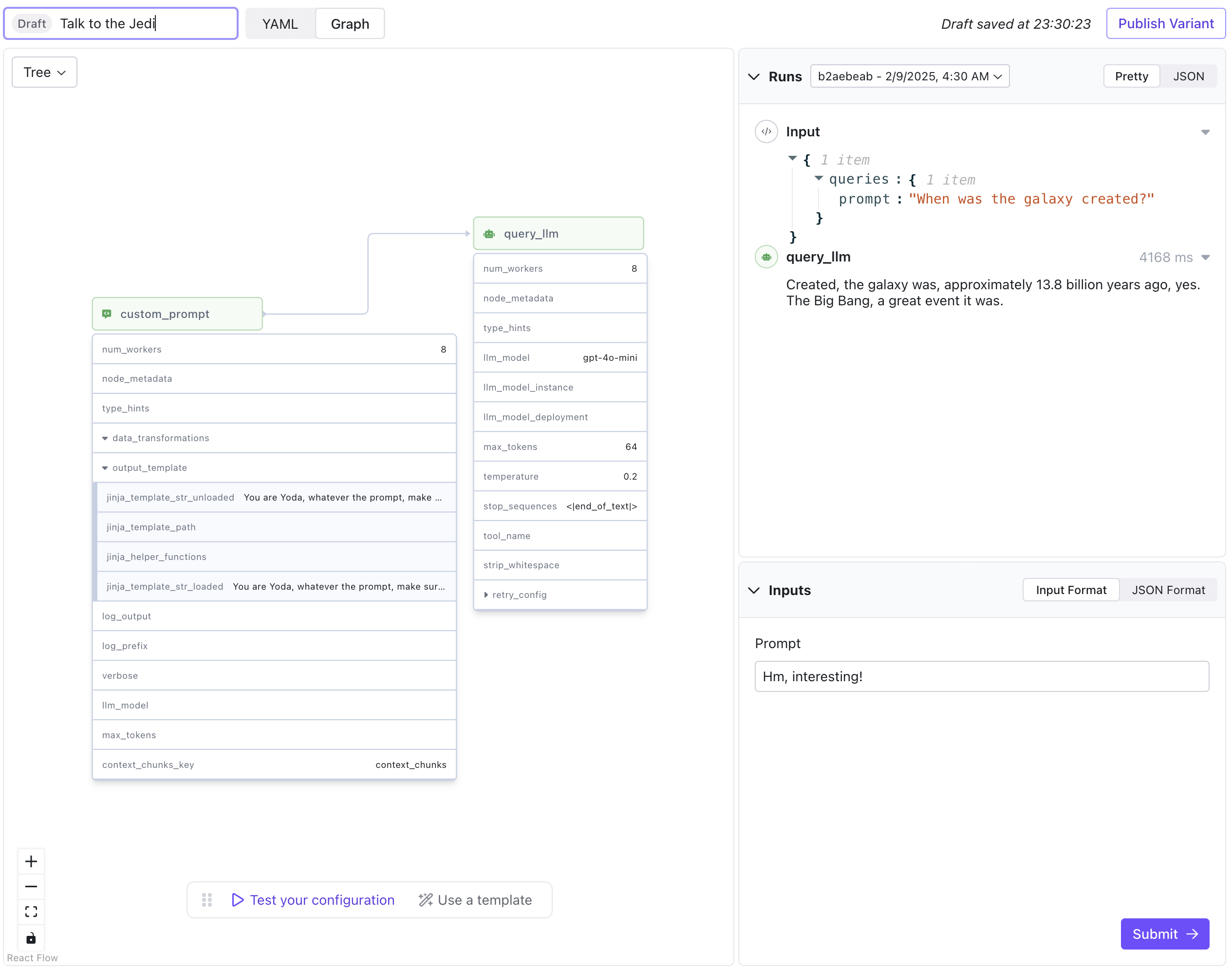
As a next step, we want build a workflow with two nodes. First we format a custom prompt, then we use this prompt to call an LLM.What It Does
-
Customizing the Prompt: The
custom_promptnode injects a fixed directive into the user’s provided text. This directive tells the model to “be Yoda” when formulating its response. This simple manipulation makes it easy to experiment with persona-based responses without complex multi-turn conversation logic. -
Generating the Response: The modified prompt is then forwarded to the
query_llmnode, which generates a response using the"gpt-4o-mini"model. The response is limited in length and controlled by specified generation parameters.
What Is New?
User Input
Specifically outlines the inputs an end user will have to provide to the workflow. This is required as the first node might have inputs that are not typed or have multiple inputs which are not all to be provided by the user.Jinja Node
Used to format inputs for nodes, such as the prompt. Inputs can be referenced as variables.Connecting Nodes
For the LLM call node, we do not directly use a user input, but use the output of the query formatting done in the Jinja node as the input. This is how nodes are connected in a workflowMulti-Turn Chat
In this example, we use the same nodes and concepts, but demonstrate how the Jinja node can be used to do complex formatting, including if statements and for loops to enable a multi-turn chat conversation.What It Does
-
Formats Conversation Data: The first node (
query_prompt) transforms a series of conversation messages into a single, structured prompt using an inline Jinja template. It:- Checks for and properly formats a system message (if present).
- Iterates over the remaining messages, formatting each with role headers and delimiters.
- Adds an assistant header at the end if the conversation ends with a user message, signaling the LLM to generate a response.
-
Generates a Response: The second node (
query_llm) takes the formatted prompt and passes it to the"gpt-4o-mini"model to generate a text response. The response is constrained by the token limit, temperature settings, and stop sequences to ensure the output is clear and concise.
How It Works
This workflow consists of two main steps: a prompt formatting stage and a generation stage.User Input
- Definition: The workflow begins by defining a
user_inputsection where the keymessagesis declared with a type ofMessages. - Purpose: This ensures that the workflow expects structured conversation data (such as a list of message objects) when the application is run.
Step 1 – Prompt Formatting with Jinja (query_prompt Node)
-
Node Type:
jinja -
Purpose: The
query_promptnode formats the conversation history into a single prompt string that is suitable for sending to the LLM. -
Jinja Template Explained: The
jinja_template_stris defined inline within the YAML. Here’s what it does:- Beginning of Text: The template starts with the token
<|begin_of_text|>, which can be used by the LLM to recognize the start of the prompt. - Handling System Messages:
- Check for a System Message: The template checks if the first message in the
messagesarray has a role of"system". - If True:
- It separates the system message from the rest of the messages by assigning the remaining messages to
loop_messages. - It formats the system message by wrapping the role with
<|start_header_id|>and<|end_header_id|>, appending the stripped content, and terminating it with<|eot_id|>.
- It separates the system message from the rest of the messages by assigning the remaining messages to
- If False:
- It sets
loop_messagesto include all messages. - No system message is added (i.e.,
system_messageis an empty string).
- It sets
- Check for a System Message: The template checks if the first message in the
- Looping Through Messages:
The template iterates over
loop_messages:- First Message in the Loop: If it’s the first message in the loop (
loop.index0 == 0), it outputs thesystem_message(if one was defined). - Formatting Each Message: For every message, it outputs:
- A header that marks the message’s role (e.g.,
userorassistant), formatted with<|start_header_id|>and<|end_header_id|>. - The message content, stripped of extra whitespace, followed by
<|eot_id|>to signal the end of that message.
- A header that marks the message’s role (e.g.,
- Prompting the Assistant: If the last message in the conversation is from the user (
loop.last and message['role'] == 'user'), the template appends an empty header for theassistant. This cues the LLM that it should generate a response.
- First Message in the Loop: If it’s the first message in the loop (
- Beginning of Text: The template starts with the token
-
Input Mapping: The node receives its input via the key
messages, which comes from the overalluser_input.
Step 2 – LLM Generation (query_llm Node)
-
Node Type:
generation - Purpose: This node takes the formatted prompt from the previous step and uses it to generate a response from an LLM.
-
Configuration Details:
- llm_model: Uses
"gpt-4o-mini", a variant of GPT-4 optimized for this use case. - max_tokens: Limits the response to 64 tokens.
- temperature: Set to
0.2for controlled and less random output. - stop_sequences: Specifies
["<|eot_id|>"]as a stopping point for the model, ensuring that it stops generating once the designated token is reached.
- llm_model: Uses
-
Input Mapping: The node receives its
input_promptfrom the output of thequery_promptnode (query_prompt.output).