file_id to the image for inputs, outputs, and traces, and these images will be rendered on the platform’s UI. This guide will walk through an example of an external application and flexible evaluation that has multimodal inputs and outputs.
This tutorial assumes that you already have a file hosted in either a publicly available server or in the SGP platform.
If you have an image that is hosted in a publicly available server, enter the path to that image under file_id.
If you need a place to host the images, follow these instructions to upload your file to the SGP platform and obtain the file_id.
Steps:
- Initialize the SGP Client.
- Application Setup.
- Define Multimodal Test Cases.
- Create Multimodal Dataset from Test Cases.
- Generate Outputs for the Application based on the Dataset.
- Create Question Set.
- Create Evaluation Run.
- Annotate Evaluation Run.
Initialize the SGP client
Follow the instructions in the Quickstart Guide to setup the SGP Client. After installing the client, you can import and initialize the client as follows:Application Setup
Evaluations are tied to an external application variant. You will first need to initialize an external application before you can evaluate your multimodal application. The following example walks you through creating an external application and variant through the SDK.Define multimodal test cases
To evaluate your multimodal application, first create a flexible evaluation dataset with test cases. Each test case should include afile_id pointing to the multimedia input and optionally a query.
If you have an image that is hosted in a publicly available server, enter the path to that image under file_id. If you need a place to host the images, follow these instructions to upload your file to the SGP platform and obtain the file_id.
Create the multimodal dataset
Once you have all your test cases ready, you can upload your data via theDatasetBuilder.
Generate Outputs
Next, generate outputs for the evaluation dataset. You can also upload multimedia traces by adding
file_ids in the traces. These traces will show up as images in the annotation view as well. generate_outputs function will run you application on the dataset and upload responses to SGP.
You can see that we already wrapped this in an External Application, so you can easily call evaluation on this.
Let’s use your runner to run the test-cases with the application. This step will generate the outputs and upload as evaluation test-case results.
Create question set
An evaluation also needs a question set. You can create a question set either through the UI or through the SDK. Here is an SDK example below:Create evaluation
Once you have your data uploaded, we are ready to start an evaluation. You will need an evaluation config. Create a custom annotation configuration to configure the layout of what annotators will see, and create the evaluation. For more details about annotation configurations, see the annotation configuration section in the Flexible Evaluations Guide.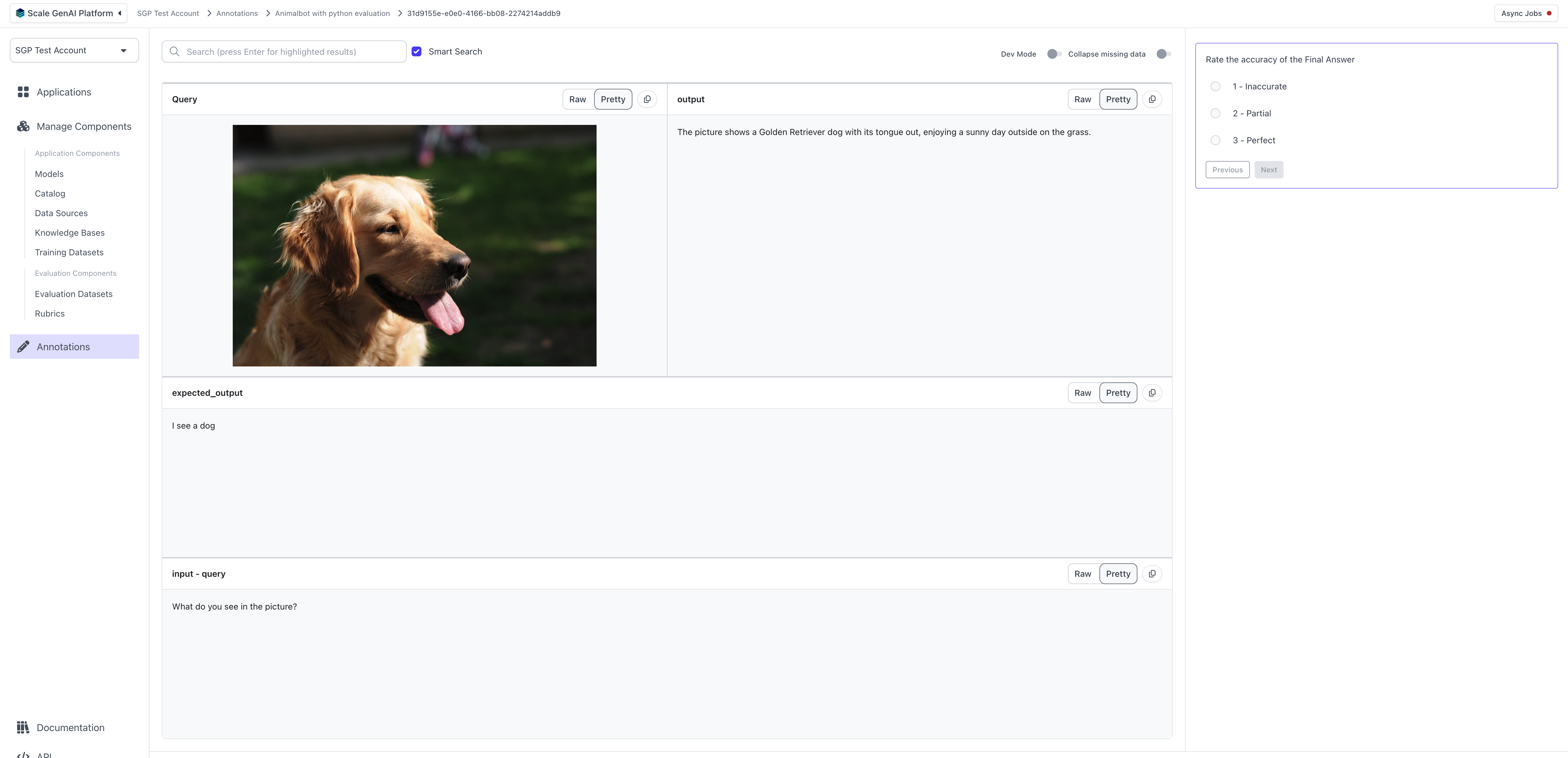
Annotate Tasks
Similar to other evaluation runs, you will find a new task queue in the annotation tab after creating the evaluations.