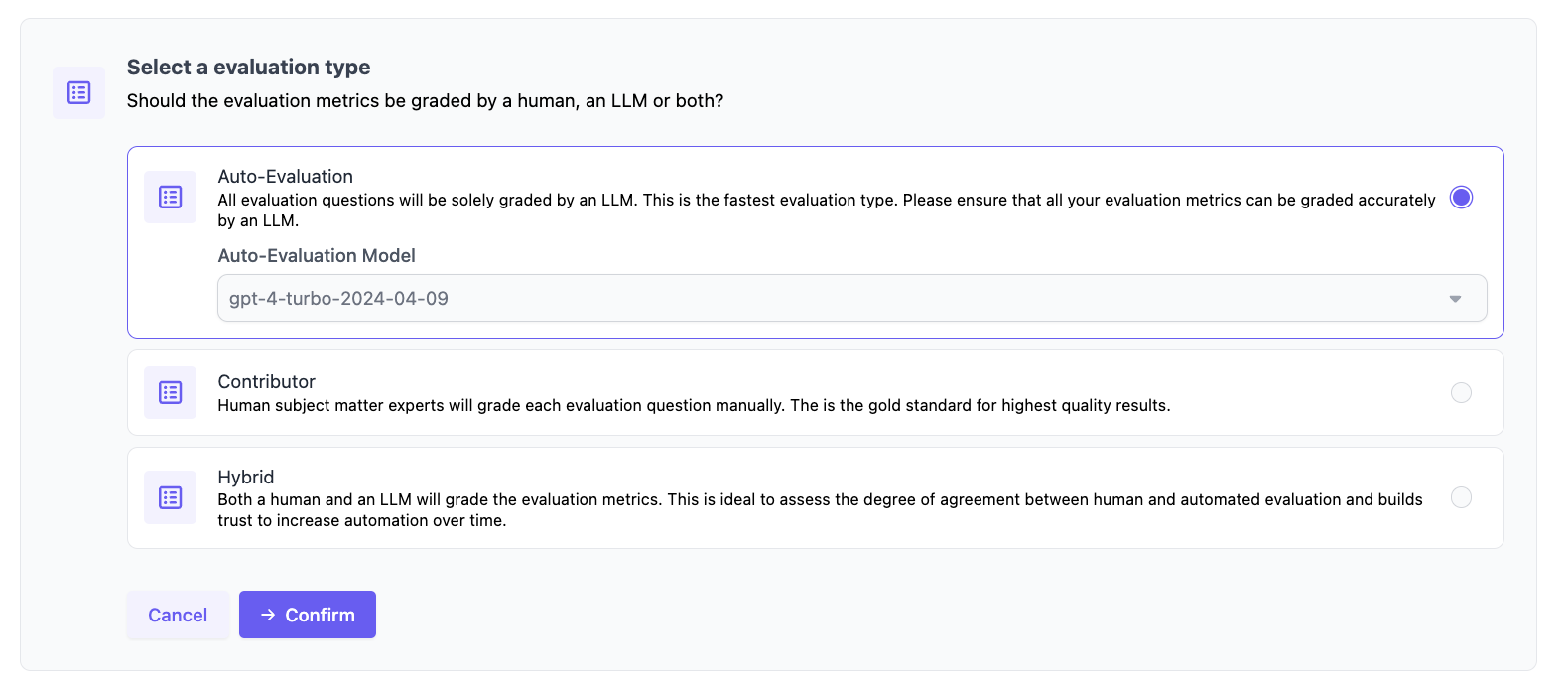
How to run an autoevaluation
For generation datasets, you will be able to select auto-evaluation when configuring the evaluation run. When configuring the evaluation run on the variant, you can either select Auto-Evaluation or Hybrid to enable an auto evaluation on the run (hybrid evaluations will run both an auto-evaluation and enable humans to annotate).