Types of Models
Real-world GenAI applications, especially when leveraging Retrieval Augmented Generation (RAG) often use multiple models, namely completion, embedding and reranking models.Completion and Chat Completion Models
A completion model predicts and generates text or content to complete a given input. It uses patterns and context from the input data to generate coherent and contextually relevant outputs. Completion models are widely employed in tasks like auto-completion, text suggestion, and code generation, enhancing user experience and productivity. A chat completion is very similar to a completion, with the difference that it operates on a list of user and AI interactions rather than a single prompt input. These are the most visible part of a GenAI application, as they provide the eventual response to a user query.Embedding Models
An embedding model transforms words into numerical vectors, representing semantic meaning in a continuous vector space. It enhances language processing, enabling machines to understand context and relationships, crucial for tasks like sentiment analysis and translation. Popular methods include Word2Vec, GloVe, BERT, and GPT. Embedding models are used to transform raw text or images, that should be used for Retrieval into a semantically searchable format. Learn more about this process in the guide for Retrieval Embedding.Reranking Models
A reranking model is designed to refine and reorder the results generated by an initial model or system. It evaluates and assigns scores to outputs based on additional criteria, ensuring the most relevant and accurate items appear at the top. This enhances the overall performance and effectiveness of information retrieval systems. Reranking models are also used for Retrieval, namely to order the context retrieved from a knowledge base in terms of its relevance to the user question.Agents
An agent is an AI component that utilizes a Language Model (LLM) as an interpreter and decision maker. Unlike LLMs, agents do not need to respond immediately to user requests. Instead, they can call upon user-defined tools for specialized information. These tools are functions that enable the agent to perform specific tasks, such as calculations, web searches, or accessing custom data from private knowledge bases. Learn more about Agents. Here is a list of each model type and links to their corresponding request and response schemas.Models in the GenAI Platform
On the Scale GenAI Platform, we have a unified backend infrastructure for hosting, fine-tuning and serving models. However, we offer two different interaction patterns with these for our users: built-in models and custom models.Built-In Models
Built-in models are models that are pre-installed in any instance of Scale GP. These include embedding, reranking and completion (as well as chat completion) models. What is unique about these pre-installed models, is that they can be called in our API just by referencing their unique name. Please refer to our Model Zoo to see which are the currently supported built-in models. We try to keep this set comprehensive and up to date with the latest available LLMs, but please contact us if you want to add a new model to the Model Zoo We have created this interaction pattern to make it fast and easy to use common base models (open source and commercial) before creating custom, more advanced models for specific use cases. Here is an example of calling a built-in model by name:Python
Custom Models
To get started immediately feel free to jump to our tutorial Create and Execute a Model A Custom Model is the standard representation of a model in Scale GP (hence, whenever we refer to “Models”, this typically means custom models). Scale GP allows users to create, deploy and fine-tune all kinds of commercial or open-source models for their specific use cases. A custom model has multiple components: a model template (only for self-hosted models), a model instance and a model deployment. Additionally, multiple model instances can be grouped into a a model group. The result is the following architecture: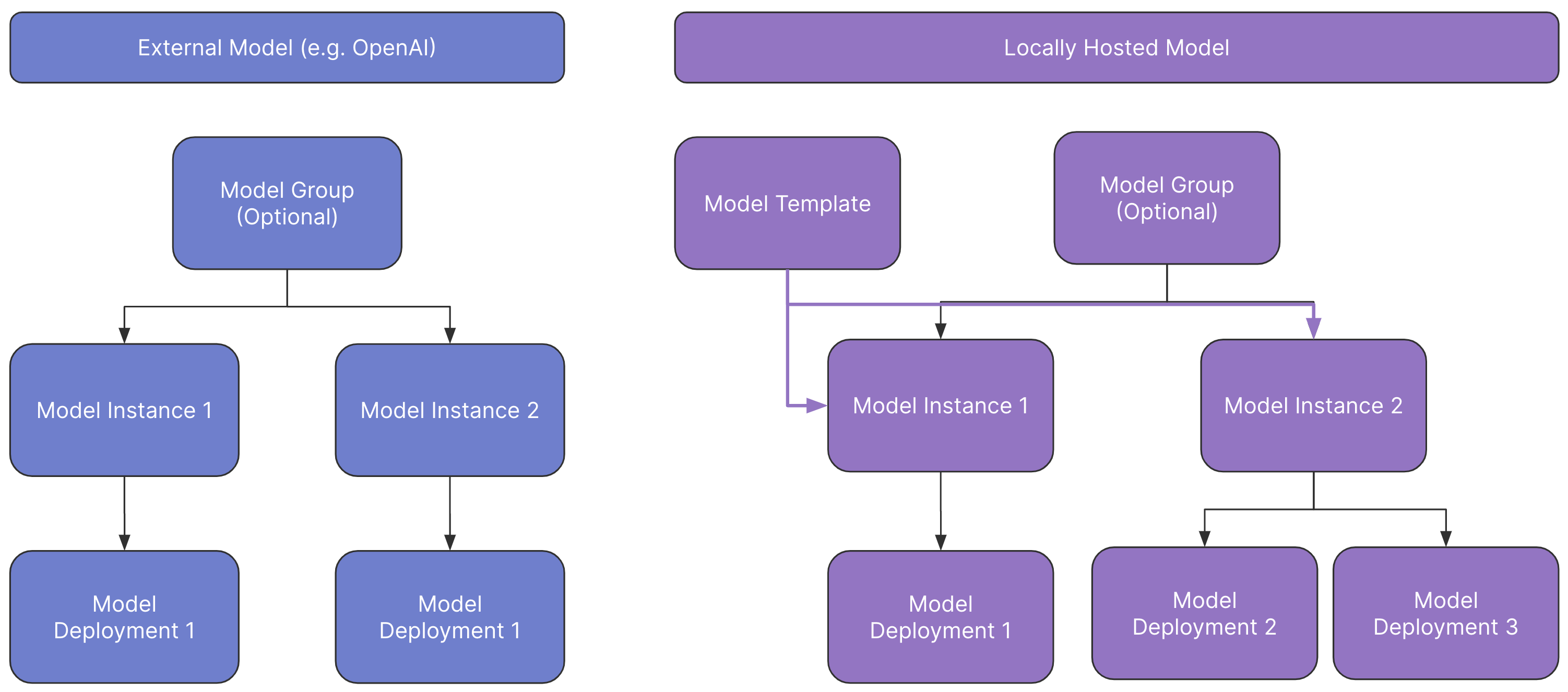
Information Architecture of Custom Models in Scale GP
Model Template
A Model Template is a static configuration for a model that defines how it should be loaded and executed. When a Model Instance is created, the configuration of the model template can be used to reserve the required computing resources, pull the correct docker image, etc. A Model Template, by definition, is static and incomplete. It expects certain parameters to be provided when a Model is created. For example, a Model Template may define a docker image that loads and executes model, but it will not specify where the model weights are loaded from. This information is provided when a Model is created. For security reasons, only admin users can create and modify model templates. Externally hosted models, like OpenAI models, do not require a model template.Model Instance
A model instance is the representation of a given set of model weights and metadata. It has all the information needed to create an actually executable model deployment.Model Deployment
A model deployment is creating a unique endpoint and ID that can be called upon using the API/SDK. The deployment is also used to log calls and monitor the usage of the given deployment Contrary to built-in models, custom models are used by executing a model deployment, referring to it by its unique ID. See an example below:Python
Model Group
A model group is a collection of model instances. It is only a namespace, which can be used to semantically group multiple iterations of a model, especially as it is being fine-tuned.Fine-Tuning
Custom models can be fine-tuned on Scale GP, either in a self-service manner or by Scale forward deployed engineers.What Models do I have?
To get a list of all custom models available in your account, you can run:Python