Create Evaluation
Navigate to the Evaluate tab and click “Create evaluation”.
Add Evaluation Details
Add in Evaluation name, description (optional), tags (optional), and select a dataset.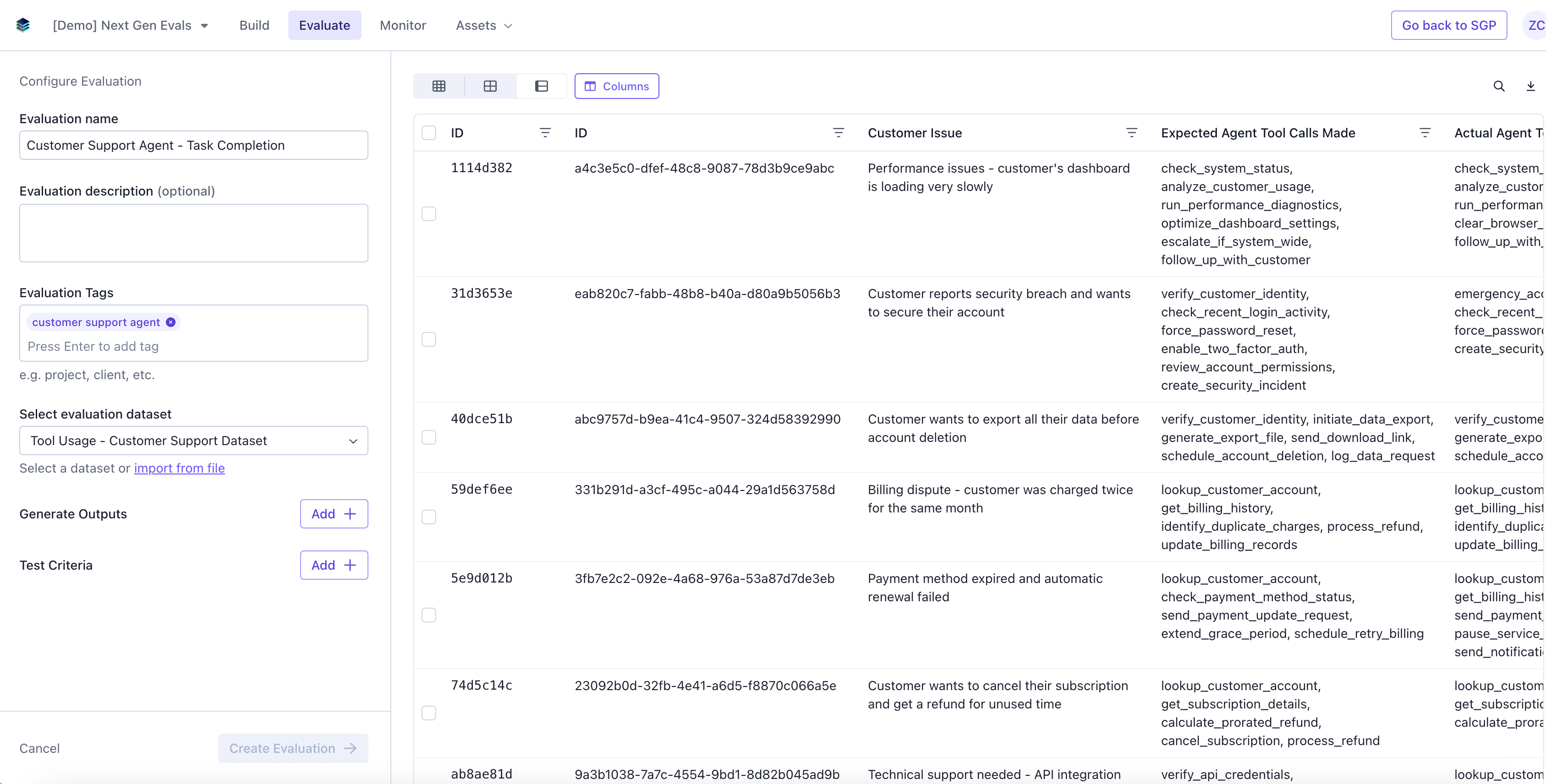
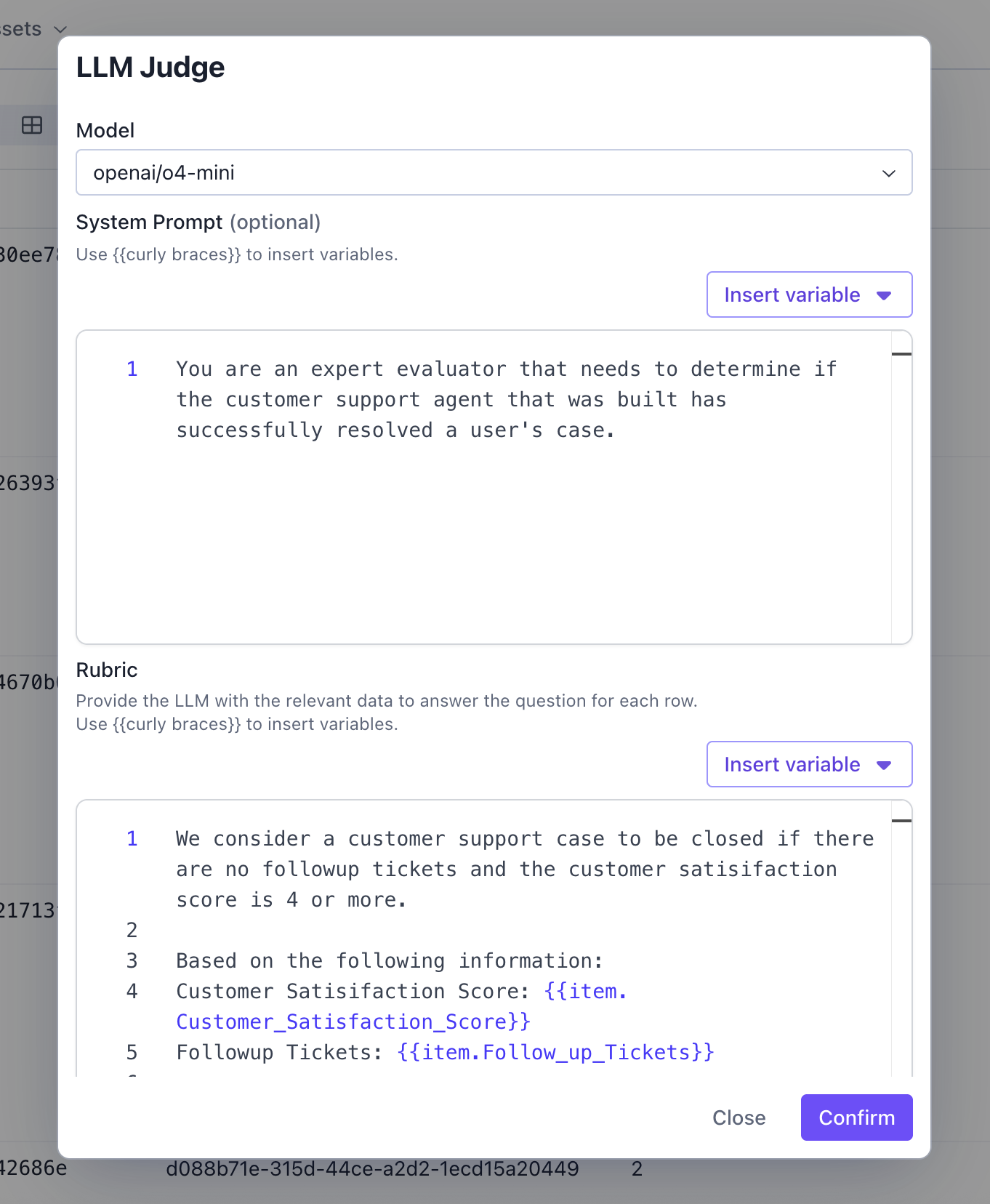
Add an LLM Judge
An LLM Judge prompts an LLM to answer questions to evaluate your dataset. You can either select an existing judge or you can configure a new one.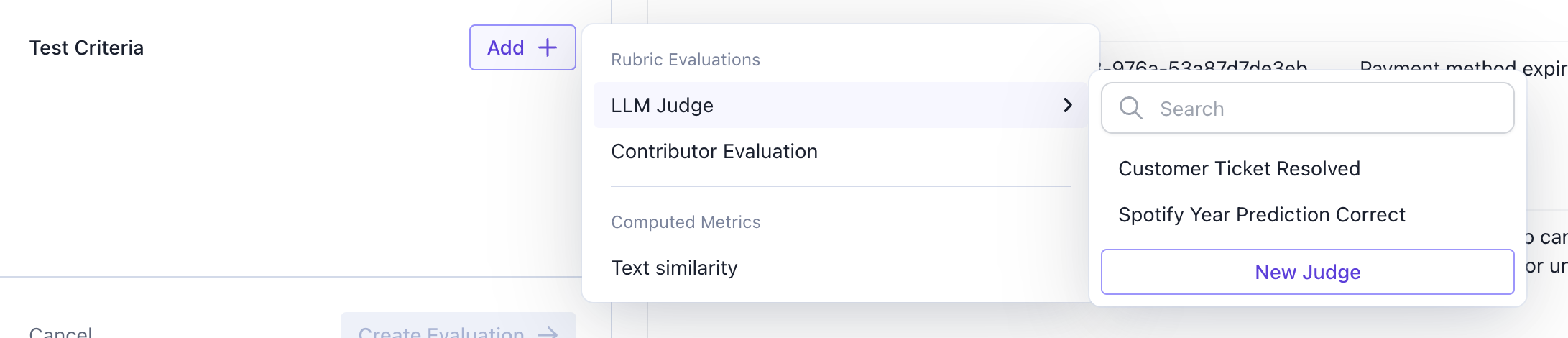
Configure LLM Judge
An LLM Judge prompts an LLM to answer questions to evaluate your dataset.- Alias (Optional) - The name of the column the results of this judge will show up on your evaluation results.
- Model - The model that the LLM Judge uses to evaluate the dataset.
- System Prompt (Optional) - A system prompt for an LLM judge is a set of instructions that defines the role and evaluation criteria for a large language model when it’s used to assess, score, or make decisions about AI outputs, human responses, or other content.
- Rubric - A rubric for an LLM judge is a structured scoring framework that defines specific evaluation criteria, performance levels, and descriptors to ensure consistent and objective assessment of AI outputs or responses.
- Response Options - Constraints to what your Model can output.
Create Evaluation
Select the rows on the dataset you want to run the evaluation, and click Create Evaluation.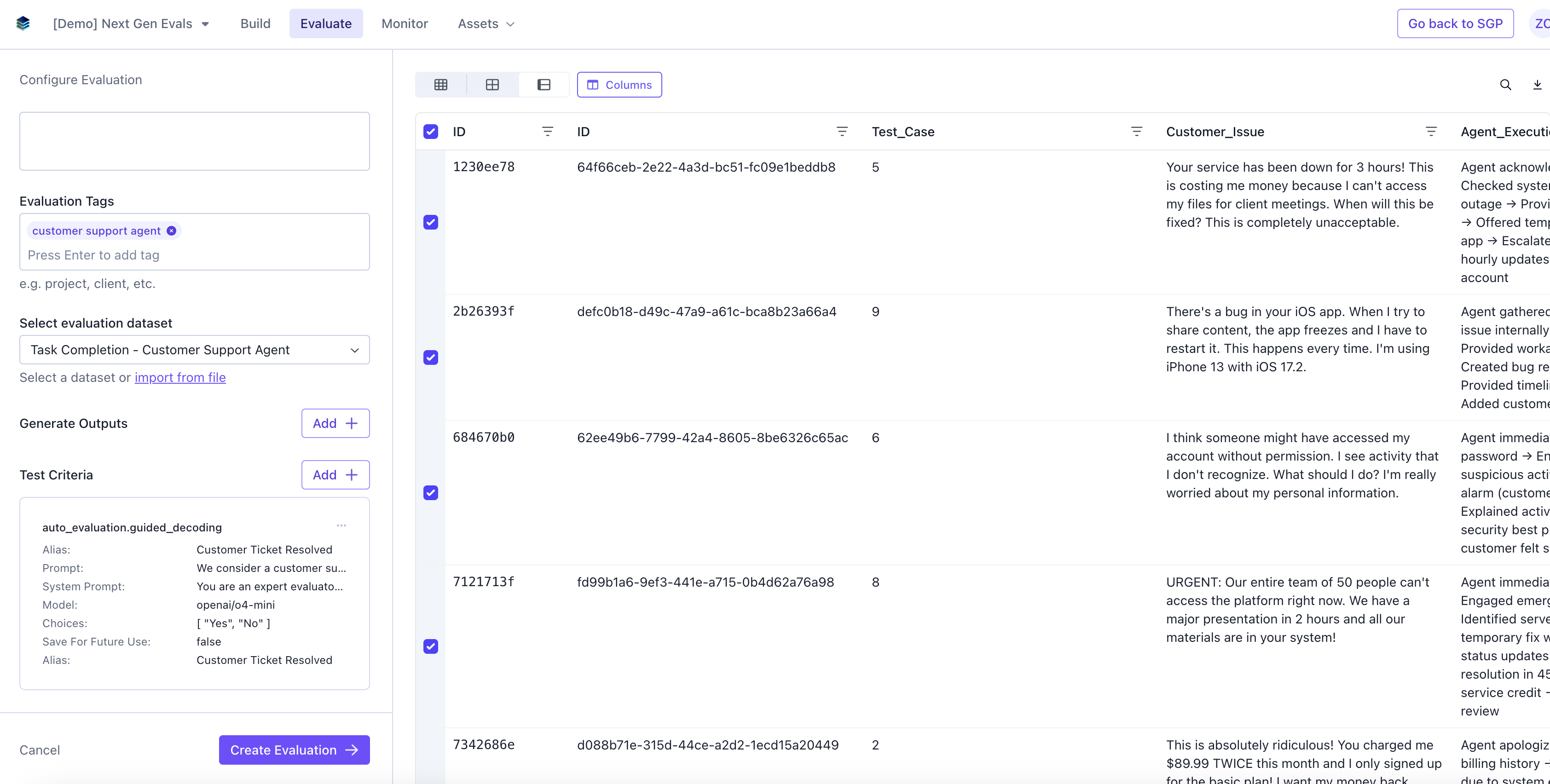
View Evaluation Results
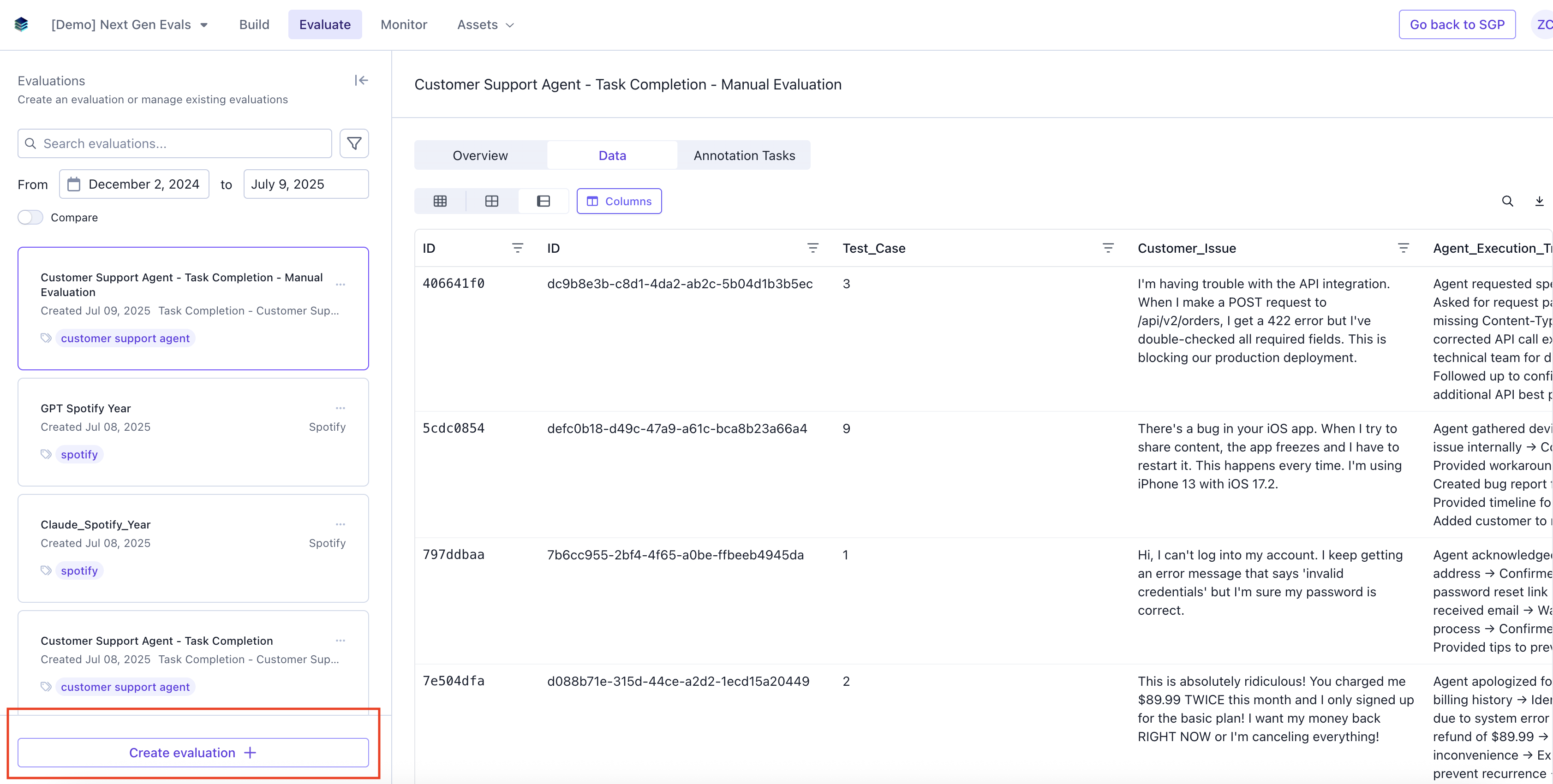
If you navigate back to the Evaluation tab, you should be able to see the results of the evaluation.Data
The data page will have a column with the results of the LLM Judge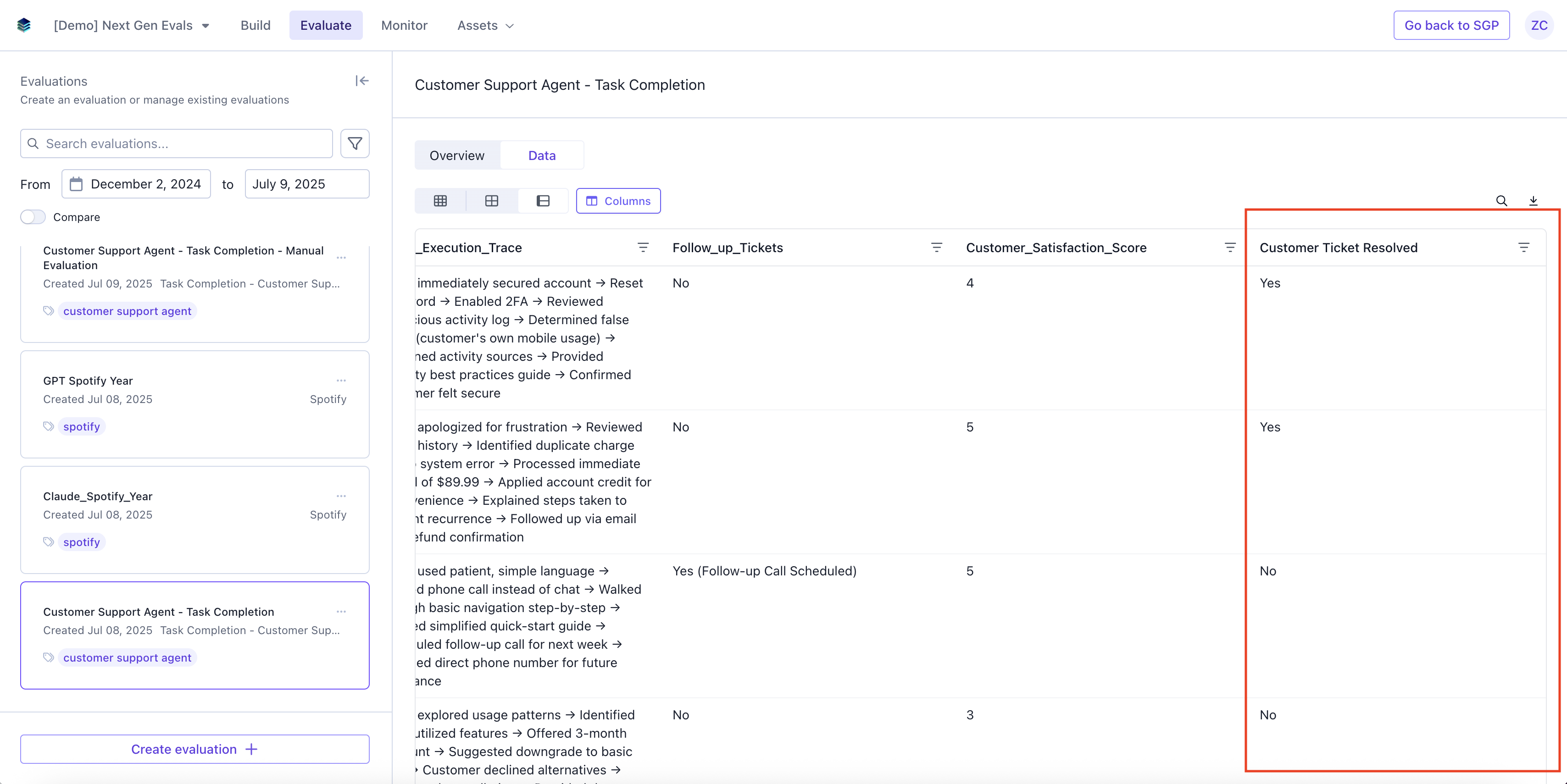
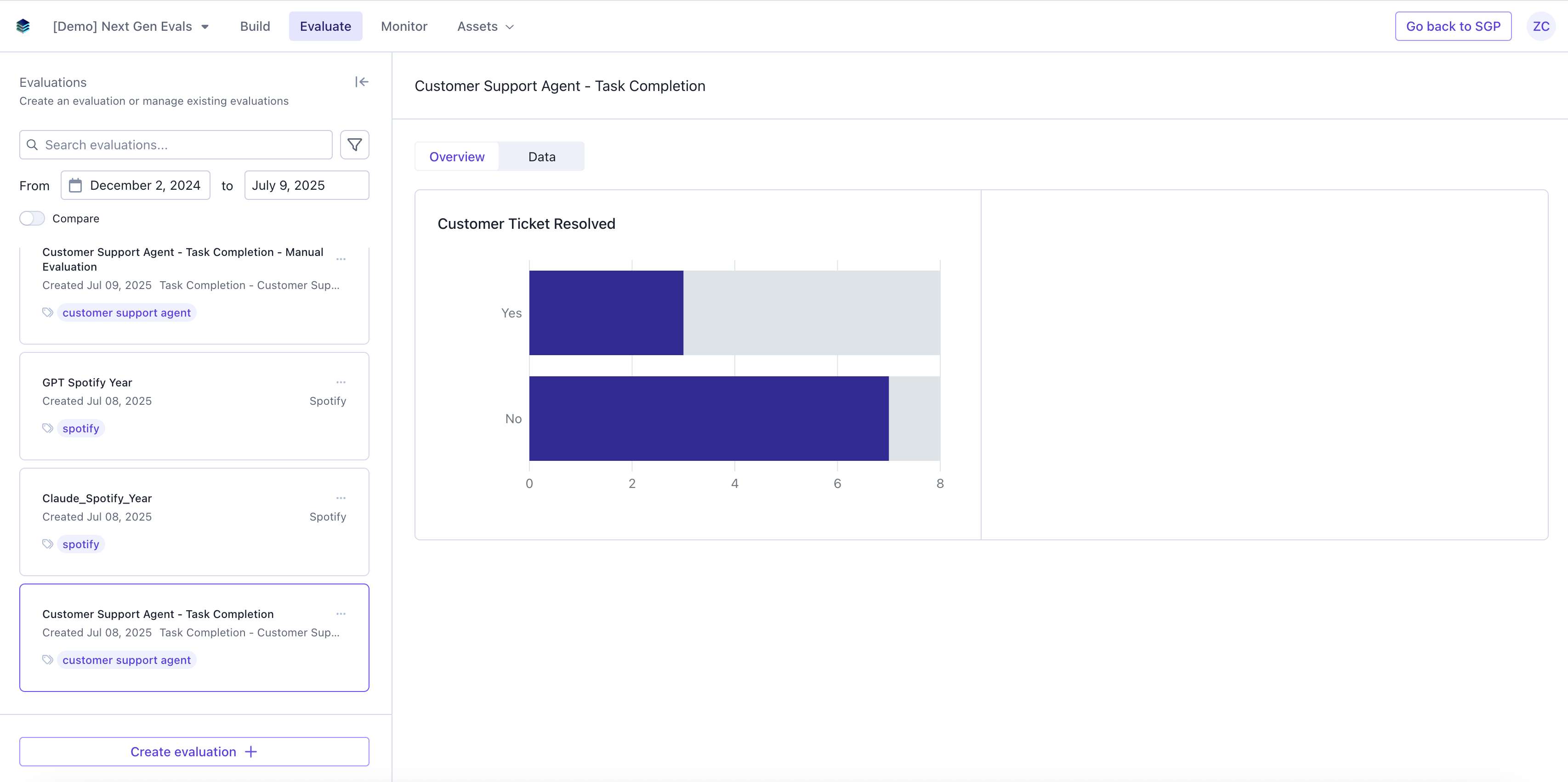
Overview
The overview page will have a graph with the visual representation of the evaluation result.